1. Infra Technique in Big Data
빅데이터의 분석만큼이나 더욱 중요한건 데이터의 수집과 관리이다.
실제로 데이터 분석(Analysis)단계보다 초기단계의 데이터 수집과 관리(Collection and Management)가 훨씬 큰 비중을 차지한다. 100%의 전체 비중에서 보았을때
Collection and Management : 95% vs Analysis : 5%
라고 많이들 이야기한다.
물론 이러한 데이터 수집과 관리를 유용하게 하는 다양한 툴들이 있다.
1) Hadoop
HDFS(Hadoop Distributed File System)기반의 오픈소스이다. 다양한 데이터 서버를 이용해 Virtual HDFS를 구성하고, MapReduce Framework를 통해 큰 사이즈의 데이터를 처리한다.
여기서 드는 의문 : HDFS는 뭐고 Mapreduce란 무엇인가..?
아주 간단히 이해만 하고 넘어가자면
- HDFS
빅데이터를 저장 및 관리하기 위한 분산시스템이다. 하나의 큰 데이터를 여러개의 블록형태로 나누어 분산된 서버에 저장 및 관리하는 시스템.

NameNode에는 분산시스템의 모든 MetaData를 관리한다. Secondary NameNode는 Fault tolereance 및 일시적 backup을 담당, 마지막 DataNode는 블록단위의 데이터를 저장, 관리하는 서버로 클라이언트 입출력요청을 관리한다.
-MapReduce Framework
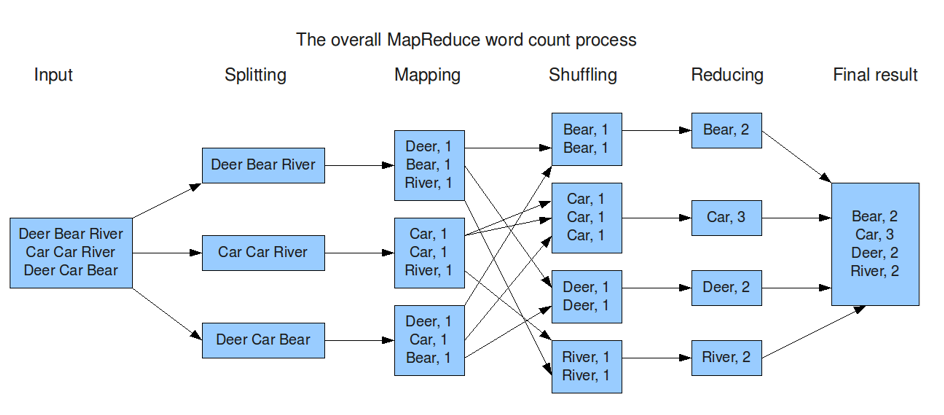
HDFS를 통해 분산된 데이터를 맵핑하고 축소(reducing)하는 방법이라고 이해하면 되겠다. 위의 그림을 통해 보면 Mapping -> Shuffling -> Reducing과정을 볼 수 있다.
요약하자면 Hadoop은 HDFS와 Mapreduce를 통한 분산 및 병렬처리를 통해 효율과 속도를 높인 빅데이터 처리방법이라고 생각하면된다.
2)Spark
스파크는 맵리듀스와 유사한 일괄처리기능을 사용한다. 하둡의 단점은 맵리듀스시에 job에 필요한 데이터를 매번 가져와야하는 비효율성이었다. 하지만 Spark는 데이터를 메모리에 캐시로 저장하는 모델로 하둡에 비해 속도나 메모리 측면에서 높은 성능을 보여준다. 또한 Java, Scala, Python등 다양한 언어를 지원하는 장점도 있다.
2. Purpose of Big Data Analysis
빅데이터 분석의 목적을 우리는 크게 5가지로 나눠볼수 있다.
- Classification and prediction
- Association and recommendation
- Clustering
- Anomaly detection
- Generation
각각의 예시는 이미 많이 나와 있고 알려져 있으니 넘어가도록 하겠다.
3. Implication and What to do
지금까지의 내용을 바탕으로 데이터 분석에서 우리가 고려해야할 요소는 아래와 같다.
1) 빅데이터의 Infra 구축이 우선이다. 하지만 이것이 목적자체가 되어선 안된다.
- ROI를 고려하자 -> 구축해봤자 쓸데가 없으면 의미 X
2) insde Data와 Outside data를 활용할 필요가 있다.
3) 목적을 정하는것이 중요하다
4) 기초 통계와 데이터마이닝은 시작점이 될 수 있다.
Reference : Data mining Class material, Hanyang Univ
'ML,DL,Bigdata > Data Mining' 카테고리의 다른 글
| 데이터 전처리(Sampling, Handling, Partition 등) (0) | 2020.08.08 |
|---|---|
| 2. Data Visualization (0) | 2020.07.19 |
| 1. Introduction to Data Mining (0) | 2020.07.09 |