오늘은 R을 이용한 데이터시각화 예제를 몇가지 다뤄볼 것이다.

데이터 분석을 크게 3가지로 나타내면 Data processing(데이터처리), Modeling(모델링), Visualization(시각화)로 나타낼 수 있다.
기본 통계적 방법을 이용한 시각화(회귀분석 그래프, 산점도, 히스토그램 등)의 예제는 제외하고 오늘은 titanic 데이터를 이용해 시각화 예제를 다뤄보자.
1) Data, package load
#데이터 & 패키지 불러오기
library(data.table)
library(ggplot2)
titanic = read.csv('titanic.csv')https://cran.r-project.org/web/packages/data.table/vignettes/datatable-intro.html
Introduction to data.table
a) What is data.table? data.table is an R package that provides an enhanced version of data.frames, which are the standard data structure for storing data in base R. In the Data section above, we already created a data.table using fread(). We can also crea
cran.r-project.org
https://cran.r-project.org/web/packages/ggplot2/ggplot2.pdf
각 데이터에 대한 Doument에 대한 링크이니 참조
data.table 패키지는 db형태의 자료구조를 다루는 R 패키지중 하나이다. 이전까지 R 데이터 처리를 할때 보통 데이터프레임 data.frame을 사용하였는데, data.table은 data.frame을 상속한 것으로 더욱 빠른 성능과 간단한 코딩이 가능하다.
ggplot2 패키지는 데이터프레임 형태의 데이터를 다양한 시각화 그래프로 나타낼 수 있게 해주는 시각화패키지이다. 요소를 하나씩 덧씌우는 방식으로 그래프를 그려나가는 방식이다.
2) Data processing
#데이터테이블 형태로 변환
>titanic.dt = as.data.table(titanic)> head(titanic.dt)
X pclass survived name sex age sibsp parch ticket fare cabin embarked boat body home.dest
1: 1 1st 1 Allen, Miss. Elisabeth Walton female 29.0000 0 0 24160 211.3375 B5 Southampton 2 NA St Louis, MO
2: 2 1st 1 Allison, Master. Hudson Trevor male 0.9167 1 2 113781 151.5500 C22 C26 Southampton 11 NA Montreal, PQ / Chesterville, ON
3: 3 1st 0 Allison, Miss. Helen Loraine female 2.0000 1 2 113781 151.5500 C22 C26 Southampton NA Montreal, PQ / Chesterville, ON
4: 4 1st 0 Allison, Mr. Hudson Joshua Crei male 30.0000 1 2 113781 151.5500 C22 C26 Southampton 135 Montreal, PQ / Chesterville, ON
5: 5 1st 0 Allison, Mrs. Hudson J C (Bessi female 25.0000 1 2 113781 151.5500 C22 C26 Southampton NA Montreal, PQ / Chesterville, ON
6: 6 1st 1 Anderson, Mr. Harry male 48.0000 0 0 19952 26.5500 E12 Southampton 3 NA New York, NY
데이터의 구성을 보면 x(승객고유번호), 등급(pclass), 생존여부(survived), 이름, 나이, 성별 등으로 구성되어있다.
>titanic.dt$survived = as.factor(titanic.dt$isminor)생존여부가 0,1 상태로 인코딩되어있다. 앞으로 우리는 factor별 생존률을 시각화해볼것이기 때문에 survived의 정보를 factor로 인코딩해준다.
#어린이, 어른 분류 (15세 미만은 어린이)
>titanic.dt[,isminor:='adult']
>titanic.dt[age<15,isminor:='child']
>titanic.dt$isminor = as.factor(titanic.dt$isminor)>head(titanic.dt)
X pclass survived name sex age sibsp parch ticket fare cabin embarked boat body home.dest
1: 1 1st 1 Allen, Miss. Elisabeth Walton female 29.0000 0 0 24160 211.3375 B5 Southampton 2 NA St Louis, MO
2: 2 1st 1 Allison, Master. Hudson Trevor male 0.9167 1 2 113781 151.5500 C22 C26 Southampton 11 NA Montreal, PQ / Chesterville, ON
3: 3 1st 0 Allison, Miss. Helen Loraine female 2.0000 1 2 113781 151.5500 C22 C26 Southampton NA Montreal, PQ / Chesterville, ON
4: 4 1st 0 Allison, Mr. Hudson Joshua Crei male 30.0000 1 2 113781 151.5500 C22 C26 Southampton 135 Montreal, PQ / Chesterville, ON
5: 5 1st 0 Allison, Mrs. Hudson J C (Bessi female 25.0000 1 2 113781 151.5500 C22 C26 Southampton NA Montreal, PQ / Chesterville, ON
6: 6 1st 1 Anderson, Mr. Harry male 48.0000 0 0 19952 26.5500 E12 Southampton 3 NA New York, NY
isminor
1: adult
2: child
3: child
4: adult
5: adult
6: adultisminor라는 column을 새로 추가하여 15세미만의 승객은 'child', 나머지는 'adult'라는 factor로 표현해준다.
#등급별 생존률
>titanic.dt[,length(which(survived==1))/nrow(.SD),by=pclass]
pclass V1
1: 1st 0.6191950
2: 2nd 0.4296029
3: 3rd 0.2552891
#성별에 따른 생존률
>titanic.dt[,length(which(survived==1)/nrow(.SD),by=sex]
sex V1
1: female 0.7274678
2: male 0.1909846
#등급/성별에 따른 생존률
>survival_pclass_sex = titanic.dt[,list(cntsurv=length(which(survived==1)),cntdie=length(which(survived==0))),by=list(pclass,sex)][,list(psurvived=cntsurv/(cntsurv+cntdie)),by=list(pclass,sex)]
>survival_pclass_sex
pclass sex psurvived
1: 1st female 0.9652778
2: 1st male 0.3407821
3: 2nd male 0.1461988
4: 2nd female 0.8867925
5: 3rd male 0.1521298
6: 3rd female 0.4907407살아남은(survived==1)사람들의 수를 등급, 나이의 개수기반의 Subset Dataframe(SD) 나눠 생존률을 구해보았다.
또 등급과 성별 분류에 따른 생존자, 사망자수를 이용해 생존률을 계산해보았다.
3)Visualization
위에서 구한 생존률을 ggplot을 이용해 그래프(히트맵)형태로 나타내보자.
> ggplot(survived_pclass_sex,aes(pclass,sex))+geom_tile(aes(fill=psurvived))+scale_fill_gradient2('survival rate')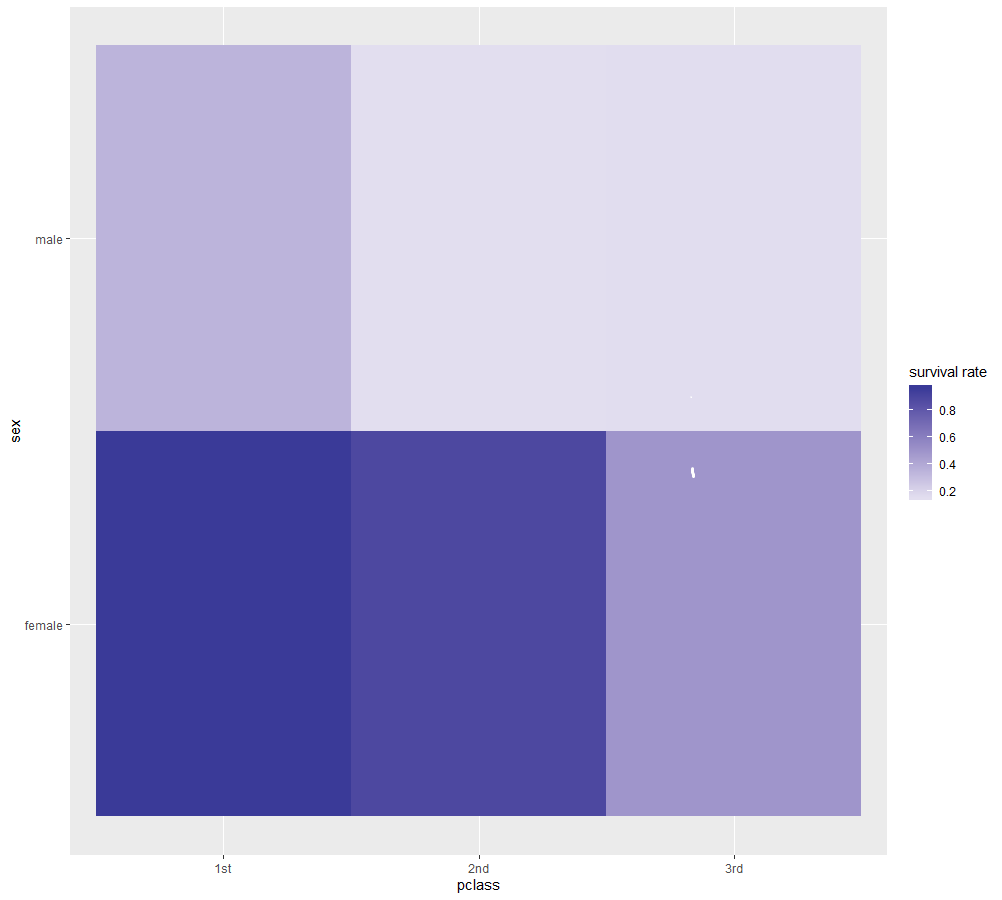
ggplot에서 aes(aesthetic-미학요소)정의로 데이터 변수 맵핑,+geom_tile을 이용해서 히트맵 형성했다.
>survived_pclass_sex_isminor = titanic.dt[,list(cntsurv=length(which(survived==1)),cntdie=length(which(survived==0))),
by=list(pclass,sex,isminor)][,list(psurvived=cntsurv/(cntsurv+cntdie)),by=list(pclass,sex,isminor)]
>survived_pclass_sex_isminor$sex_age = apply(survived_pclass_sex_isminor[,list(sex,isminor)],1,paste,collapse='_')
>ggplot(survived_pclass_sex_isminor,aes(pclass,sex_age))+
geom_tile(aes(fill=psurvived))+scale_fill_gradient2('survivalrate',low=muted('white'),high=muted('blue'))
위에서 계산했던 방법과 같은 방법으로 isminor(15세미만 어린이인지 아닌지) 요소를 추가하여 등급, 성별, 나이에 따른 생존률을 계산하였다. apply를 이용해 성별에 따른 어린이, 어른을 네가지로 구별하는 록 하였다. (ex)여자어린이,여자어른, 남자어린이, 남자어른.) 요소가 3개이기 때문에 2차원인 히트맵으로 표현하기 위해서 해준것!
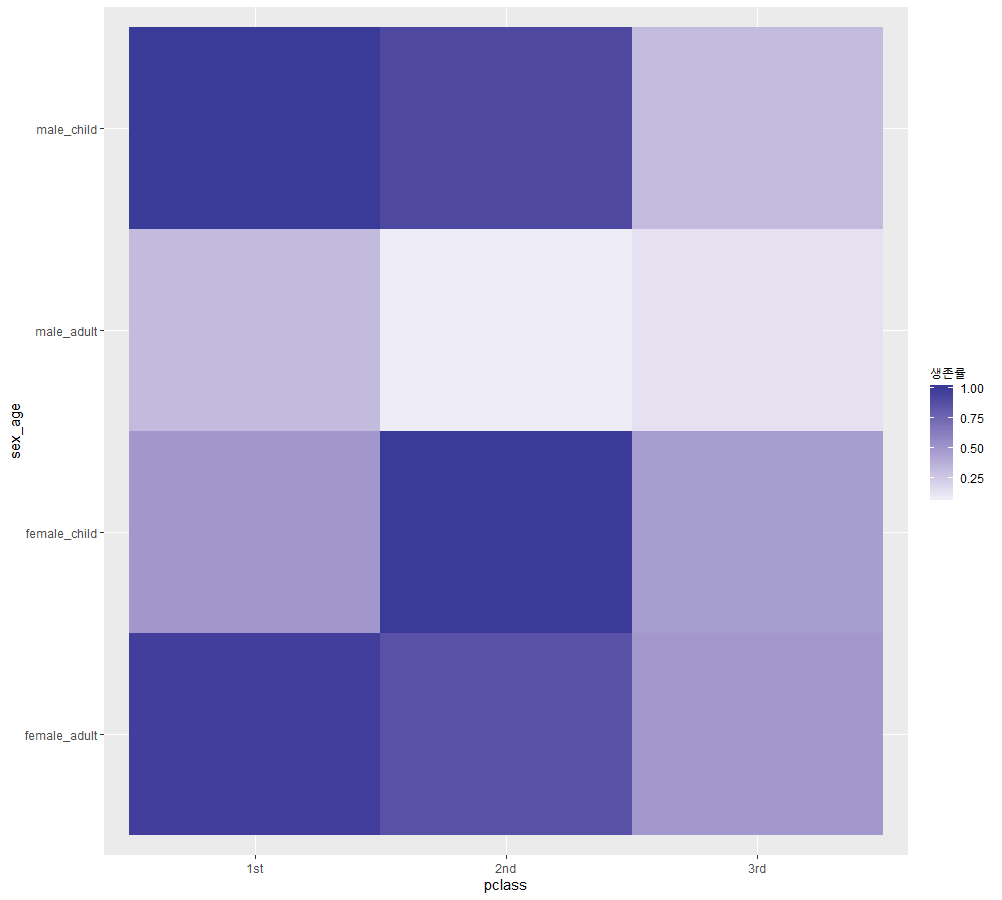
히트맵으로 표현한 결과는 위와 같다!
Reference : Data mining class material, Hanyang univ
'ML,DL,Bigdata > Data Mining' 카테고리의 다른 글
| 데이터 전처리(Sampling, Handling, Partition 등) (0) | 2020.08.08 |
|---|---|
| 1-2. Process and Purpose of Big Data Analysis (0) | 2020.07.10 |
| 1. Introduction to Data Mining (0) | 2020.07.09 |