데이터의 처리에 대해서 알아보자. 데이터 전처리라 하면 너무 포괄적인 개념이지만 몇몇가지 중요 개념 위주로 살펴볼 것이다.
내용으로 들어가기 전에 데이터마이닝의 기본단계를 살펴보자
- Define/understand purpose
- Obtain data (may involve random sampling)
- Explore, clean, pre-process
- Reduce the data; if suprevised DM, partition it
- Specify task (classification, clustering etc.)
- Choose the techniques(regression, Neural networks, etc)
- Iterative implementation and tuning
- Assess result - compare models
- Deploy best model
우리가 오늘 집중적으로 살펴볼 단계는 2번부터 4번까지의 단계라고 보면 된다. 이를 통합적으로 표현할 적당한 단어가 전처리라고 생각하여 전처리라는 표현을 사용했다.
Sampling
샘플링은 2번 단계에 해당되는, 즉 데이터 확보시에 사용되는 기법이다.
데이터마이닝은 대개 큰 규모의 데이터셋을 사용한다. 하지만 우리가 관심있는 사건(event)가 너무 많거나 너무 적은경우 모델을 학습시키거나 알고리즘을 적용하는데에 적절하지 않다. (일반적으론 사건이 적은 경우가 대부분)
예를 들어 우리가 카드사용내역의 fraud detection을 한다고 가정해보자. 우리에게 10만개의 데이터셋이 있다면 실제로문제가 일어난 경우(fraud)는 10만개중 극히 일부에 불과할 것이다. (이게 너무 많다면 큰 문제가 있을것이다..)
이러한 문제들을 해결하기 위해 사용하는 기법이 샘플링 기법이다. 오늘은 이렇게 적은 케이스의 문제에 주로 사용되는 oversampling에 대해서 알아보자.

데이터에서 우리가 관심없는 major class가 존재할 것이고, 관심있는 minor class가 존재할 것이다. 오버샘플링은 우리가 관심있는 minor class를 증식시켜 두 class의 균형을 맞추는 것이다. 그렇다면 반대로 undersampling은 우리가 관심없는 major class의 비중을 낮춰서 두 class의 균형을 유지한다. 이렇게 균형을 맞춤으로써 우리는 효과적으로 모델을 학습킬수 있게 된다.
데이터의 비중을 늘리고 낮추는 데에는 다양한 알고리즘이 사용되지만 자세한 내용은 생략하도록 하겠다.
WestRoxbury housing 데이터기반으로 R을 이용한 실습을 해보자.
일단은 데이터를 불러오고 살펴보자.
> #1. Data Exploration
> housing.df = read.csv('WestRoxbury.csv',header = TRUE)
> dim(housing.df)
[1] 5802 14
> head(housing.df)
TOTAL.VALUE TAX LOT.SQFT YR.BUILT GROSS.AREA LIVING.AREA FLOORS ROOMS BEDROOMS FULL.BATH HALF.BATH KITCHEN FIREPLACE
1 344.2 4330 9965 1880 2436 1352 2 6 3 1 1 1 0
2 412.6 5190 6590 1945 3108 1976 2 10 4 2 1 1 0
3 330.1 4152 7500 1890 2294 1371 2 8 4 1 1 1 0
4 498.6 6272 13773 1957 5032 2608 1 9 5 1 1 1 1
5 331.5 4170 5000 1910 2370 1438 2 7 3 2 0 1 0
6 337.4 4244 5142 1950 2124 1060 1 6 3 1 0 1 1
REMODEL
1 None
2 Recent
3 None
4 None
5 None
6 Old
> View(housing.df)
> summary(housing.df)
TOTAL.VALUE TAX LOT.SQFT YR.BUILT GROSS.AREA LIVING.AREA FLOORS
Min. : 105.0 Min. : 1320 Min. : 997 Min. : 0 Min. : 821 Min. : 504 Min. :1.000
1st Qu.: 325.1 1st Qu.: 4090 1st Qu.: 4772 1st Qu.:1920 1st Qu.:2347 1st Qu.:1308 1st Qu.:1.000
Median : 375.9 Median : 4728 Median : 5683 Median :1935 Median :2700 Median :1548 Median :2.000
Mean : 392.7 Mean : 4939 Mean : 6278 Mean :1937 Mean :2925 Mean :1657 Mean :1.684
3rd Qu.: 438.8 3rd Qu.: 5520 3rd Qu.: 7022 3rd Qu.:1955 3rd Qu.:3239 3rd Qu.:1874 3rd Qu.:2.000
Max. :1217.8 Max. :15319 Max. :46411 Max. :2011 Max. :8154 Max. :5289 Max. :3.000
ROOMS BEDROOMS FULL.BATH HALF.BATH KITCHEN FIREPLACE REMODEL
Min. : 3.000 Min. :1.00 Min. :1.000 Min. :0.0000 Min. :1.000 Min. :0.0000 None :4346
1st Qu.: 6.000 1st Qu.:3.00 1st Qu.:1.000 1st Qu.:0.0000 1st Qu.:1.000 1st Qu.:0.0000 Old : 581
Median : 7.000 Median :3.00 Median :1.000 Median :1.0000 Median :1.000 Median :1.0000 Recent: 875
Mean : 6.995 Mean :3.23 Mean :1.297 Mean :0.6139 Mean :1.015 Mean :0.7399
3rd Qu.: 8.000 3rd Qu.:4.00 3rd Qu.:2.000 3rd Qu.:1.0000 3rd Qu.:1.000 3rd Qu.:1.0000
Max. :14.000 Max. :9.00 Max. :5.000 Max. :3.0000 Max. :2.000 Max. :4.0000 summary에 나와있는 ROOMS의 통계량을 보면, 중간값: 7, 평균: 6.995, 3rd Quantile: 8 Max:14 이다.
만약 우리가 방 10개 이상의 데이터에 관심이 있다고 가정해보자. 3분위수의 숫자가 8이기 때문에 10개 이상의 방은 데이터셋 전체에서 작은 일부분에 해당할 것이다.
> #2. Sampling
> #random sample of 5 observations
> s = sample(row.names(housing.df),5)
> housing.df[s,]
TOTAL.VALUE TAX LOT.SQFT YR.BUILT GROSS.AREA LIVING.AREA FLOORS ROOMS BEDROOMS FULL.BATH HALF.BATH KITCHEN FIREPLACE
1943 387.3 4872 3168 1910 3048 1718 2 7 3 1 1 1 1
5523 383.6 4825 5600 1953 3078 1470 1 8 3 1 1 1 1
5366 351.8 4425 4500 1940 2436 1368 2 6 3 1 1 1 1
1195 294.5 3704 9100 1950 2060 768 1 5 2 1 0 1 0
5194 330.1 4152 4507 1950 2388 1134 1 6 2 1 0 1 0
REMODEL
1943 None
5523 Old
5366 None
1195 None
5194 None
> #oversample houses with over 10 rooms
> s = sample(row.names(housing.df),5,prob=ifelse(housing.df$ROOMS>10,0.9,0.01))
> housing.df[s,]
TOTAL.VALUE TAX LOT.SQFT YR.BUILT GROSS.AREA LIVING.AREA FLOORS ROOMS BEDROOMS FULL.BATH HALF.BATH KITCHEN FIREPLACE
3213 551.2 6934 9140 1900 6053 3348 2 9 4 1 1 1 1
2184 716.2 9009 9022 1920 4758 3132 2 13 6 2 0 1 1
1157 372.7 4688 9021 1960 2632 1196 1 8 3 2 0 1 2
4487 712.5 8963 13340 1920 6807 3771 2 12 6 2 0 1 1
3838 476.1 5989 3620 1932 4118 3058 2 11 5 2 2 1 1
REMODEL
3213 None
2184 Old
1157 Old
4487 None
3838 Recent샘플링을 한 결과이다. 첫번째로 랜덤하게 5개의 데이터를 샘플링 한 경우엔 10개 이상의 방을 가진 데이터가 하나도 안나왔다. 오버샘플링을 한 결과 5개중 3개의 데이터가 10개 이상의 방을 가지도록 샘플링 되었다.
Variable Type(Creating dummy)
위의 데이터의 REMODEL column을 보면 None, Old, Recent로 구성이 되어있다. 변수(feature)의 타입이 numeric한 나머지column과 달리 REMODEL의 경우는 categorical하다. 많은 알고리즘에서 categorical한 데이터를 그대로 사용할 수 없기 때문에 우리는 이것을 Binary dummy로 바꿔줄것이다.
> #4. Creating binary dummies
> #use model.matrix() to convert all categorical variables in the data frame into
> #a set of dummy variables. we must then turn the resulting data matrix back into
> #a data frame for further work
> xtotal = model.matrix(~0+BEDROOMS+REMODEL,data=housing.df)
> xtotal = as.data.frame(xtotal)
> t(t(names(xtotal))) #check the names of dummy variable
[,1]
[1,] "BEDROOMS"
[2,] "REMODELNone"
[3,] "REMODELOld"
[4,] "REMODELRecent"
> head(xtotal)
BEDROOMS REMODELNone REMODELOld REMODELRecent
1 3 1 0 0
2 4 0 0 1
3 4 1 0 0
4 5 1 0 0
5 3 1 0 0
6 3 0 1 0
> xtotal = xtotal[,-4] #Drop one of the dummy variables
> head(xtotal)
BEDROOMS REMODELNone REMODELOld
1 3 1 0
2 4 0 0
3 4 1 0
4 5 1 0
5 3 1 0
6 3 0 1
> #put it all together again, drop original REMODEL from the data
> housing.df = cbind(housing.df[,-c(9,14)],xtotal)
> t(t(names(housing.df)))
[,1]
[1,] "TOTAL.VALUE"
[2,] "TAX"
[3,] "LOT.SQFT"
[4,] "YR.BUILT"
[5,] "GROSS.AREA"
[6,] "LIVING.AREA"
[7,] "FLOORS"
[8,] "ROOMS"
[9,] "FULL.BATH"
[10,] "HALF.BATH"
[11,] "KITCHEN"
[12,] "FIREPLACE"
[13,] "BEDROOMS"
[14,] "REMODELNone"
[15,] "REMODELOld" REMODEL을 3개의 dummy variable로 바꾸고 마지막 더미 하나를 삭제시켜 기존의 데이터셋에 추가했다.
마지막 더미 하나를 빼준 이유는 linear independent를 유지해주기 위해서. (0,0,1)의 경우는 (0,0)으로도 표현 가능하다.
Handling Missing data
많은 경우에 데이터에서 결측치가 발생할 수 있다. 많은 알고리즘이 결측치를 처리하지 못하기 때문에 우리는 전처리 과정에서 결측치 문제를 해결해야 한다.
다양한 방법이 있겠지만 가장 단순한 방법은 결측치를 포함하는 데이터를 제외하는것이다. 결측치를 가지는 데이터의 수가 아주 적은경우 그 데이터를 제거한다. 혹은 몇몇 소수의 variable(feature)에 너무 많은 결측치가 존재하는 경우엔 그 variable(feature)를 빼버릴 수 있다. 하지만 많은 데이터에 결측치가 골고루 있다면 적합하지 않은 방법이다
그래서 우리는 결측치를 적절한 대체값으로 대체하는 방법을 사용할 수 있다. 가장 단순하게 평균값이나 중간값을 사용해도 되지만 여기에도 적용할 수 있는 많은 기법들이 존재한다. (R에서는 MICE, Amelia, missForest 등의 패키지 사용 가능하다)
> #5. Missing Data
> #주어진데이터엔 missing value 없으므로 임의로 random
> #missing value 생성
> rows.to.missing = sample(row.names(housing.df),10)
> housing.df[rows.to.missing,]$BEDROOMS = NA
> summary(housing.df$BEDROOMS)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.00 3.00 3.00 3.23 4.00 9.00 10
> #na.rm=TRUE로 해서 median 계산할때 missingvalue 무시
> #missing value를 median으로 대체
> housing.df[rows.to.missing,]$BEDROOMS = median(housing.df$BEDROOMS,na.rm=TRUE)
> summary(housing.df$BEDROOMS)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 3.000 3.000 3.229 4.000 9.000 임의로 10개의 missing value를 10개 생성하였다. 여기서는 간단히 median값으로 missing value값을 대체하였다.
Normalizing(Standardizing) Data
데이터 중 몇몇 feature들의 스케일이 너무 큰 경우, 나머지 feature들이 지배되거나 스케일이 큰 데이터에 기울어진 학습 결과를 나타낼 수 있으므로 효과적인 학습이 힘들 수 있다. 이를 위해 데이터를 normalizing해주는 것이 필요하다.
Partition
모델을 학습시키다 보면 때때로 모델이 지나치게 training set에 과적합(overfitting)되어 새로운 데이터에 대해 모델이 잘 잘동하지 않을 수 있다. 이를 방지하기 위해 우리는 데이터셋을 분할하여 Validation set을 형성해준다.
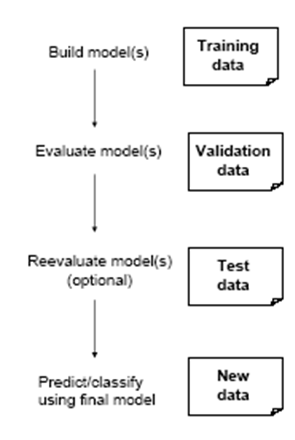
Training set으로 모델을 학습시키고, validation을 통해 모델이 새로운 데이터에 적합한지 확인한 후 test를 진행한다. 이러한 방법을 통해 overfitting 문제를 대처할 수 있다.

기존의 데이터셋을 위와 같은 방법으로 분할하여 validation 과정을 통해 과적합 문제를 해결한다. 그러나 어떤 모델을 같은 validation set에 대해서만 평가하다 보면 validation data가 과적합 되버리는 경우가 생길 수 있다. 또 어떤 방법은 validation data를 사용하여 parameter를 선택하기도 하는데 이또한 과적합의 문제를 야기할 수 있다. 그래서 우리는 test data를 사용하여 새로운 데이터에 대해 검증을 해준다.

혹은 위와 같은 방법으로 test set에 중복없이 교차검증을 진행하기도 하는데, 이러한 경우 test set을 하나로 고정시키지 않음으로써 과적합을 방지한다.
> #6. Data Partitioning in R
> #use set.seed() to get the same partitions when re-running the R code
> set.seed(1) #random 설정시 set.seed해놓으면 항상 같은 random생성
> #디버깅이나 reproducible한 코딩 할때 필요로함
> #1)60% training set, 40% validation set
> train.rows = sample(rownames(housing.df),dim(housing.df)[1]*0.6)
> train.data = housing.df[train.rows,]
> #row id가 training set에 없는것 즉 남은것 validation
> valid.rows = setdiff(rownames(housing.df),train.rows)
> valid.data = housing.df[valid.rows,]
> dim(train.data)
[1] 3481 15
> dim(valid.data)
[1] 2321 15총 데이터셋을 60% / 40% 의 비율의 training, validation set으로 나눈 결과이다.
> #2)training 50% validation 30% test 20%
> train.rows = sample(rownames(housing.df),dim(housing.df)[1]*0.5)
> valid.rows = sample(setdiff(rownames(housing.df),train.rows),dim(housing.df)[1]*0.3)
> test.rows = setdiff(rownames(housing.df),union(train.rows,valid.rows))
> train.data = housing.df[train.rows,]
> valid.data = housing.df[valid.rows,]
> test.data = housing.df[test.rows,]
> dim(train.data)
[1] 2901 15
> dim(valid.data)
[1] 1740 15
> dim(test.data)
[1] 1161 15위에서 언급한 validation의 과적합 방지를 위해 test set까지 5:3:2의 비율로 나눈 결과이다.
Fit model & Scoring the validation data
> #7.fit model to the training data
> #use lm(linear model) function
> reg = lm(TOTAL_VALUE~.,data = housing.df,subset = train.rows)
> summary(reg) #tax 요소가 너무 dominated.
Call:
lm(formula = TOTAL_VALUE ~ ., data = housing.df, subset = train.rows)
Residuals:
Min 1Q Median 3Q Max
-0.043617 -0.019592 -0.000234 0.019827 0.042017
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 9.486e-03 3.819e-02 0.248 0.8039
TAX 7.949e-02 8.011e-07 99230.046 <2e-16 ***
LOT.SQFT 3.280e-07 2.068e-07 1.586 0.1128
YR.BUILT 1.288e-05 1.932e-05 0.667 0.5050
GROSS.AREA 1.269e-06 1.260e-06 1.007 0.3141
LIVING.AREA -4.626e-06 2.327e-06 -1.988 0.0469 *
FLOORS 7.954e-04 1.345e-03 0.591 0.5543
ROOMS 1.682e-04 4.922e-04 0.342 0.7325
FULL.BATH 2.359e-03 1.031e-03 2.289 0.0222 *
HALF.BATH 1.009e-03 9.588e-04 1.053 0.2926
KITCHEN 1.545e-03 3.459e-03 0.447 0.6551
FIREPLACE -5.509e-04 8.147e-04 -0.676 0.4990
BEDROOMS 4.216e-04 7.644e-04 0.551 0.5813
REMODELNone 4.248e-04 1.314e-03 0.323 0.7465
REMODELOld 6.383e-04 1.751e-03 0.364 0.7155
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.02279 on 2886 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: 1
F-statistic: 4.053e+09 on 14 and 2886 DF, p-value: < 2.2e-16
> #remove tax
> reg = lm(TOTAL_VALUE~.-TAX,data = housing.df,subset=train.rows)
> summary(reg)
Call:
lm(formula = TOTAL_VALUE ~ . - TAX, data = housing.df, subset = train.rows)
Residuals:
Min 1Q Median 3Q Max
-286.301 -24.671 -0.175 24.581 229.298
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.907e+02 7.044e+01 -2.707 0.006837 **
LOT.SQFT 9.094e-03 3.423e-04 26.565 < 2e-16 ***
YR.BUILT 1.366e-01 3.558e-02 3.839 0.000126 ***
GROSS.AREA 3.278e-02 2.245e-03 14.602 < 2e-16 ***
LIVING.AREA 5.032e-02 4.194e-03 11.998 < 2e-16 ***
FLOORS 4.163e+01 2.360e+00 17.642 < 2e-16 ***
ROOMS 1.540e+00 9.085e-01 1.696 0.090053 .
FULL.BATH 1.805e+01 1.873e+00 9.634 < 2e-16 ***
HALF.BATH 1.843e+01 1.737e+00 10.608 < 2e-16 ***
KITCHEN -1.873e+01 6.379e+00 -2.936 0.003347 **
FIREPLACE 1.901e+01 1.462e+00 13.000 < 2e-16 ***
BEDROOMS -2.325e+00 1.411e+00 -1.648 0.099513 .
REMODELNone -2.523e+01 2.381e+00 -10.598 < 2e-16 ***
REMODELOld -2.150e+01 3.209e+00 -6.700 2.5e-11 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 42.09 on 2887 degrees of freedom
Multiple R-squared: 0.8264, Adjusted R-squared: 0.8257
F-statistic: 1058 on 13 and 2887 DF, p-value: < 2.2e-16training data를 linear regression을 통해 모델링해본 결과 tax에 의해 dominated되어 다른 모든 feature에 유의하지 않게 결과가 나오는듯 하다. normalizaing대신 단순히 tax를 제외하고 모델링을 해보았다.
> #'Scoring' data is getting predicted('fitted value') here for the training data
> tr.res = data.frame(train.data$TOTAL_VALUE,reg$fitted.values,reg$residuals)
> head(tr.res)
train.data.TOTAL_VALUE reg.fitted.values reg.residuals
1886 356.7 351.7781 4.921916
3515 333.3 319.2133 14.086697
460 298.6 360.0416 -61.441554
855 265.3 327.0707 -61.770684
4094 575.1 527.7868 47.313238
3581 348.0 379.0211 -31.021148
> pred = predict(reg,newdata = valid.data)
> vl.res = data.frame(valid.data$TOTAL_VALUE,pred,residuals=valid.data$TOTAL_VALUE-pred)
> head(vl.res)
valid.data.TOTAL_VALUE pred residuals
5642 318.0 370.0136 -52.013608
2766 498.7 430.3993 68.300731
3676 331.8 352.6545 -20.854476
2054 371.9 374.5730 -2.672951
2217 436.2 437.7121 -1.512077
3117 280.2 255.4699 24.730108validation set의 데이터를 모델에 넣어 score, 즉 fitted value를 구해보았다.
Asess Accuracy
> #8. Assess accuracy
> #for the validation data
> library(forecast)
Registered S3 method overwritten by 'quantmod':
method from
as.zoo.data.frame zoo
Warning message:
패키지 ‘forecast’는 R 버전 3.6.3에서 작성되었습니다
> accuracy(pred,valid.data$TOTAL_VALUE)
ME RMSE MAE MPE MAPE
Test set 0.3845983 43.14481 32.66104 -0.8576621 8.414074마지막으로 validation set에 적용한 accuracy를 metric을 통해 확인한다.
Reference : 한양대학교 이기천 교수님의 데이터마이닝 수업자료
'ML,DL,Bigdata > Data Mining' 카테고리의 다른 글
| 2. Data Visualization (0) | 2020.07.19 |
|---|---|
| 1-2. Process and Purpose of Big Data Analysis (0) | 2020.07.10 |
| 1. Introduction to Data Mining (0) | 2020.07.09 |